
发布时间:2026年4月9日,北京 | 阅读时长:约10分钟
2026年2月14日,字节跳动正式发布了豆包AI助手背后的核心引擎——豆包大模型2.0(Doubao-Seed-2.0),这是该系列自2024年5月正式发布以来首次大版本的跨代升级,标志着豆包AI助手从“被动问答”迈向“主动指导”的全新阶段-1。作为字节跳动旗下深度集成于豆包AI助手的大语言模型,豆包大模型2.0围绕大规模生产环境下的使用需求做了系统性优化,依托高效推理、多模态理解与复杂指令执行能力,致力于更好地完成真实世界的复杂任务-2。

本文将从技术科普的角度,为读者全面解析豆包AI助手的核心技术架构,涵盖多模态Agent原理、MoE混合专家架构、底层技术支撑、代码实战示例以及高频面试考点,帮助技术学习者和开发工程师建立从概念到应用的全链路知识体系。
一、痛点切入:传统AI助手的“三条软肋”
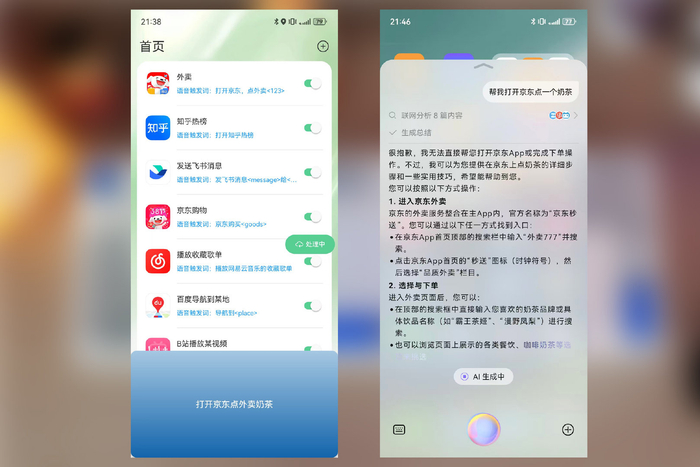
在理解豆包AI助手的革新之处前,我们先来看看传统AI助手面临的三大核心痛点:
痛点一:只能“回答问题”,不能“解决问题”
传统AI助手大多停留在“一问一答”的对话模式,用户问什么它就答什么,缺乏主动规划和执行能力。比如用户说“帮我查一下天气然后推荐适合的穿搭”,传统AI助手只能分别回答天气信息和穿搭建议,无法将两者关联并主动给出整合后的建议-。
痛点二:多轮对话“记性差”,上下文频繁断裂
很多传统AI助手采用无脑拼接历史对话的方式管理上下文,当对话轮数增加后,模型对开头内容的关键信息逐渐遗忘,导致“聊着聊着就跑题”-29。这种“记忆窗口有限”的天然缺陷,严重影响了多轮交互的连贯性。
痛点三:多模态能力薄弱,视觉理解“装看不见”
传统AI助手大多基于纯文本模型构建,面对图像、视频等多模态输入时“视而不见”或“理解浅层”,无法完成真正的视觉推理和视频流分析任务。
正是为了从根本上解决这些问题,豆包AI助手背后的豆包大模型2.0应运而生。它不再是一个“只会聊天的工具”,而是具备多模态感知、复杂推理和主动执行能力的Agent(智能体)模型。
二、核心概念讲解:什么是“豆包AI助手”与“多模态Agent”
2.1 豆包AI助手——定义与全称
豆包AI助手,英文全称为 Doubao AI Assistant,是字节跳动旗下基于豆包大模型(Doubao Large Model)构建的智能对话与任务执行平台。豆包大模型的正式模型名称为 Doubao-Seed-2.0,其中“Seed”代表字节跳动的AI研究团队“Seed团队”,“2.0”标志其从1.x系列向2.0时代的跨代升级-1-16。
通俗理解:如果把豆包AI助手比作一个“智能管家”,那么豆包大模型就是这个管家的“大脑”——负责理解用户的指令、规划执行路径、调用外部工具、最终给出答案或执行操作。
2.2 多模态Agent——核心概念
多模态Agent(Multimodal Agent),即多模态智能体,是指能够同时处理文本、图像、视频、音频等多种模态信息,并具备自主规划、工具调用和任务执行能力的人工智能系统。
Agent的四大核心能力:根据技术界共识,原生Agent需要具备感知、动作、推理、记忆四大核心能力-14。
感知(Perception):像人类一样“看”到图像、“听”到声音、“读”到文字。
动作(Action):能够调用外部工具(如、API、代码执行)来执行具体任务。
推理(Reasoning):具备逻辑思考和任务规划能力。
记忆(Memory):能够记住对话历史和任务上下文,实现多轮连贯交互。
生活化类比:把多模态Agent想象成一个“全能助理”——你给它一张照片(图像),它能识别出照片里的人在健身(视觉感知);你对它说“帮我找几个类似的健身视频”(文本指令),它能联网、筛选结果、甚至直接播放视频(工具调用与执行)。整个过程不需要你一步步指挥,助理自己就能完成从“理解”到“执行”的全链路操作。
三、关联概念讲解:豆包大模型的“家族成员”
豆包大模型2.0并非单一模型,而是由四款差异化模型组成的家族,分别适配不同场景的延迟、成本和能力需求-15:
| 模型名称 | 定位说明 | 对标产品 |
|---|---|---|
| 豆包2.0 Pro | 旗舰模型,面向深度推理与长链路任务执行 | 对标GPT 5.2、Gemini 3 Pro |
| 豆包2.0 Lite | 兼顾性能与成本,综合能力超越豆包1.8 | 性价比首选 |
| 豆包2.0 Mini | 面向低时延、高并发与成本敏感场景 | 轻量级部署 |
| 豆包2.0 Code | 专为编程场景优化的代码模型 | 与TRAE结合使用 |
概念辨析:
豆包AI助手是面向终端用户的产品形态(用户能直接对话的“智能助手”)。
豆包大模型是支撑这个产品的核心技术引擎(模型本身)。
多模态Agent是豆包大模型2.0的核心技术范式(区别于传统大模型的“思维方式”)。
一句话总结:豆包AI助手 = 豆包大模型(大脑)+ Agent能力(手和眼)+ 产品界面(对话入口)。
四、概念关系与区别总结
理解豆包AI助手的核心技术架构,关键在于理清以下三层逻辑:
第一层:豆包AI助手(产品层) → 用户直接交互的界面与体验层。
第二层:豆包大模型(模型层) → 支撑产品能力的核心引擎,包括Pro、Lite、Mini、Code四款模型。
第三层:多模态Agent(范式层) → 模型的设计理念和工作方式,强调从“对话”到“行动”的范式跃迁。
一句话记忆:豆包AI助手是“产品”,豆包大模型是“引擎”,多模态Agent是“思维方式”——三者共同构成了从技术到应用的完整闭环。
五、代码/流程示例:豆包2.0 API实战
豆包AI助手面向企业和开发者开放了火山引擎API服务,以下是使用豆包2.0 Pro模型进行简单调用的示例-2-12。
5.1 API基础调用示例
豆包2.0 API调用示例 import requests 火山引擎API配置 api_url = "https://ark.cn-beijing.volces.com/api/v3/chat/completions" api_key = "your_api_key_here" 从火山引擎控制台获取 多轮对话请求 payload = { "model": "doubao-seed-2.0-pro-32k", "messages": [ {"role": "system", "content": "你是豆包AI助手,回答需简洁准确。"}, {"role": "user", "content": "帮我分析这张图片中人物的动作,并给出健身建议。"}, 多模态输入时附加图片URL {"role": "user", "content": [{"type": "image_url", "image_url": {"url": "图片地址"}}]} ], "temperature": 0.7, "max_tokens": 500 } response = requests.post(api_url, headers={"Authorization": f"Bearer {api_key}"}, json=payload) result = response.json() print(result["choices"][0]["message"]["content"])
5.2 核心参数解读
豆包AI助手API支持以下关键控制参数-29:
| 参数 | 推荐值 | 作用说明 |
|---|---|---|
temperature | 0.5-0.8 | 控制输出随机性,数值越低越确定性 |
max_tokens | 500-2000 | 控制回复长度上限 |
top_p | 0.9 | 核采样参数,与temperature二选一 |
presence_penalty | 0.3 | 抑制重复用词,长回复场景效果明显 |
stop | ["用户:", ""] | 设置停止符,防止模型“自问自答” |
💡 实战提示:豆包2.0 Pro的定价为输入3.2元/百万tokens、输出16元/百万tokens,较业界顶尖模型降低约一个数量级-3-1。这在需要大规模推理与长链路生成的生产场景中具有显著成本优势。
六、底层原理与技术支撑
6.1 MoE(混合专家架构)
豆包大模型的核心底层技术之一是 MoE(Mixture of Experts,混合专家架构) 。简单来说,MoE是一种“术业有专攻”的神经网络设计思路:模型内部包含多个被称为“专家”的小型子网络,当输入一个token时,由门控网络(路由)决定调用哪几个专家来处理,而非让所有参数都参与运算-。
豆包深度思考模型的技术参数:总参数200B(2000亿),但激活参数仅20B,即每次推理只激活约1%的参数参与计算,在保持模型效果的同时显著降低了推理成本和延迟-。实测API服务在保障高并发的条件下,延迟可低至20毫秒-。
6.2 统一多模态预训练架构
豆包大模型采用从预训练阶段就实现端到端的统一多模态架构,而非将视觉模型和文本模型简单拼装。这种设计使模型在处理图像、视频、文本等多模态输入时,能够实现跨模态的信息对齐与协同推理-。
数据基础:依托字节跳动旗下抖音、今日头条等平台的UGC数据,豆包大模型构建了包含12万亿token的多模态数据集,其中视频数据占比高达43%,显著提升了对动态场景的理解能力-。
6.3 上下文窗口与注意力机制
豆包大模型支持最高256K的上下文窗口,这意味着它可以在一次对话中处理约50万汉字的文本量,相当于一次性“读”完一整本《三体》-。在处理长文本时,模型通过稀疏注意力机制和滑动窗口注意力等优化技术,在保证关键信息召回率的同时控制计算复杂度-。
七、企业级落地与应用场景
7.1 豆包2.0的四大落地场景
| 场景类别 | 典型应用 | 技术价值 |
|---|---|---|
| 智能客服Agent | 基于OpenClaw框架构建的全链路客服Agent,可完成客户对话、问题转接、售后回访 | 从被动应答到主动服务 |
| 智能座舱 | 别克至境E7行业首发搭载豆包大模型,实现陪伴、娱乐、用车、出行、车控五大功能 | 从指令响应到类人交互-44 |
| 媒体内容生产 | 凤凰卫视深度合作,借助豆包视频生成模型融入视频素材生成、字幕检测等流程 | AI赋能传媒全链路-41 |
| AI编程助手 | 豆包2.0 Code与TRAE结合,仅需5轮提示词即可构建复杂Web应用 | 大幅提升开发效率-12 |
7.2 核心数据一览
日均Tokens使用量:较推出初期增长超500倍-12
推理成本:较业界顶尖模型降低约一个数量级-12
HLE-text得分:54.2分,领跑全球大模型榜单-15
数学奥赛成绩:IMO、CMO数学奥赛和ICPC编程竞赛中获得金牌成绩-15
八、高频面试题与参考答案
面试题1:豆包大模型2.0的核心技术升级有哪些?
参考答案(建议背诵要点):
豆包大模型2.0的核心升级集中在三个方面:
多模态理解全面升级:视觉推理、感知能力、空间推理与长上下文理解能力达到世界顶尖水平,在TVBench等测评中领先,EgoTempo基准得分超过人类。
Agent能力大幅强化:支持思考长度可调节,多轮指令遵循、工具调用能力显著增强,可完成从“找资料—归纳—结论”的连续工作流。
推理成本大幅降低:模型效果与业界顶尖大模型相当,但token定价降低了约一个数量级,为大规模企业部署提供了经济可行性。
面试题2:什么是MoE架构?豆包是如何应用的?
参考答案:
MoE全称Mixture of Experts(混合专家架构),是一种通过门控网络动态调用专家子网络的模型设计。豆包深度思考模型采用MoE架构,总参数200B,激活参数仅20B,以1/10的计算量实现媲美顶尖模型的效果,API服务延迟可低至20毫秒。
面试题3:Agent与传统AI助手有何本质区别?
参考答案:
传统AI助手停留在“被动问答”模式,而Agent具备感知、动作、推理、记忆四大核心能力,能够自主规划任务路径、调用外部工具、在执行中动态调整策略,实现从“对话”到“行动”的范式跃迁。豆包2.0正是这一范式的代表性产品。
九、总结与展望
本文从技术科普与实战应用的双重视角,系统梳理了豆包AI助手的核心技术体系:
✅ 核心概念:豆包AI助手是基于豆包大模型构建的多模态Agent产品,具备从被动问答到主动指导的交互升级能力。
✅ 技术架构:依托MoE混合专家架构(总参数200B/激活20B)、统一多模态预训练(12万亿token/视频占43%)、256K超长上下文窗口三大底层技术。
✅ 模型家族:Pro/Lite/Mini/Code四款差异化模型,分别适配深度推理、成本均衡、低时延和编程开发等多元场景。
✅ 落地价值:已在智能座舱(别克至境E7)、媒体内容(凤凰卫视)、智能客服、AI编程(TRAE)等企业场景中实现大规模落地。
豆包AI助手正在以“多模态理解 + Agent执行 + 低成本部署”的三位一体能力,重塑大模型从实验室走向生产环境的落地路径。对于技术学习者和开发者而言,理解豆包AI助手的核心技术——从MoE架构到多模态Agent范式——不仅是掌握当前大模型技术趋势的关键一步,更是构建未来AI应用的知识基石。
📌 下篇预告:深度拆解豆包AI助手的Prompt工程与对话状态管理,从代码层揭秘如何设计高质量的多轮对话系统。敬请期待!
本文基于2026年4月9日公开信息整理,数据来源于火山引擎官方披露、字节跳动技术报告及权威媒体报道。如需最新API定价和技术参数,请访问火山方舟官网。
 扫一扫微信交流
扫一扫微信交流