

2026.04.10 怎么编辑AI助手?搜资料配置实战
在AI开发与应用领域,让助手准确并整合资料是智能体的核心能力。许多开发者发现,直接调用API往往结果泛泛、缺乏深度。本文将聚焦

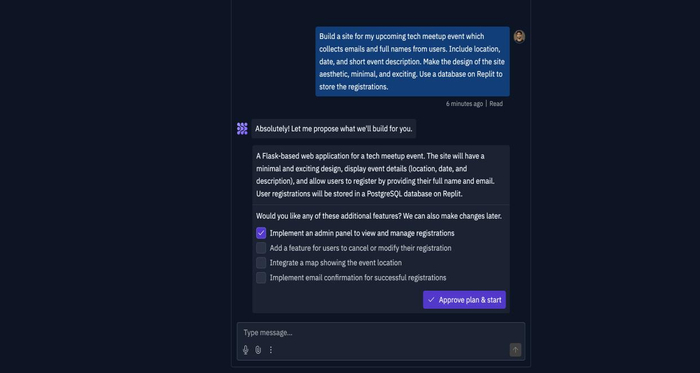
一、基础信息配置
文章标题:
2026.04.10 怎么编辑AI助手?搜资料配置实战
目标读者:技术入门/进阶学习者、在校学生、面试备考者、相关技术栈开发工程师
文章定位:技术科普 + 原理讲解 + 代码示例 + 面试要点
写作风格:条理清晰、由浅入深、通俗易懂
核心目标:理解概念、理清逻辑、看懂示例、记住考点
一、开篇引入
在检索增强生成(Retrieval-Augmented Generation, RAG)成为大模型落地标配的今天,资料的能力直接决定了AI助手的实用性。初学者的常见痛点是:只会用现成的联网插件,一遇到复杂资料(如特定格式的财报、技术文档片段)就束手无策;不懂背后的重排序(Re-ranking)、分块(Chunking)原理;面试时被问到“如何优化RAG召回率”时答不出。
本文将从怎么编辑AI助手的底层配置入手,涵盖提示词工程、检索参数调优及代码级集成。这是系列文章的第一篇,后续会深入探讨混合检索与微调。
二、痛点切入:为什么需要编辑资料方式?传统的AI助手资料,通常采用全量嵌入+固定阈值召回。我们来看一个伪代码流程:
传统方式:简单拼接用户问题 + 全网 def simple_search(query): results = search_api(query, top_k=5) return "\n".join([r.text for r in results]) 使用 query = "2026年最新的Go语言并发模型" print(simple_search(query))
传统方式的缺点:
耦合高:逻辑硬编码在助手内部,无法针对特定领域(如医学、法律)调整。
扩展性差:无法同时接入多个数据源(内部Wiki + 外部新闻 + PDF文档)。
结果冗余:固定返回5条结果,未做相关性重排,大量无用信息混入。
维护困难:当需求变化(如要求“只返回2026年4月后的结果”),必须修改底层代码。
怎么编辑AI助手的资料流程,核心就是设计一套可配置、可编排的检索管线。
三、核心概念讲解:系统提示词(System Prompt)标准定义:系统提示词是预设给AI模型的顶层指令,它位于对话历史的最前端,用于定义助手的角色、行为边界和输出格式。
关键词拆解:
系统:最高优先级,用户无法覆盖。
提示词:自然语言形式的编程指令。
生活类比:如果把AI助手比作一个新入职的实习生,系统提示词就是员工手册。手册规定了他(角色:资料研究员)、工作流程(收到问题后,必须先检索内部知识库,再去)、输出规范(必须标注信息来源和发布时间)。
作用:通过精心编写系统提示词,我们可以编辑AI助手的策略。例如,要求它“在资料时,优先选用arxiv.org和GitHub官方文档,忽略个人博客,并对每个结果给出可信度评分”。
四、关联概念讲解:检索参数(Retrieval Parameters)标准定义:检索参数是调用向量数据库或API时传递的配置值,用于控制检索行为的粒度、数量和相似度阈值。
核心参数与作用:
top_k:返回最相似的K个文档块。chunk_size:将长文档切割成块的大小(如512 tokens)。similarity_threshold:相似度分数低于此值的结果将被丢弃。
它与系统提示词的关系:系统提示词是“思想”(告诉AI要怎么做),检索参数是“手段”(具体怎么做)。
系统提示词:
“你是一个严谨的学术研究员,资料时必须优先采用权威源。”检索参数:
top_k=10, similarity_threshold=0.75
对比差异:
| 概念 | 层次 | 可修改性 | 影响范围 |
|---|---|---|---|
| 系统提示词 | 策略层 | 随时编辑 | AI的思考与输出风格 |
| 检索参数 | 执行层 | 代码配置 | 向量库召回的数量与质量 |
简单示例:同样“Transformer解码器原理”,设置top_k=3和top_k=20,后者会召回更多长尾内容,但噪声也更多。
逻辑关系:系统提示词是策略制定者(高维),检索参数是执行配置者(低维)。二者共同构成“怎么编辑AI助手资料”的完整技术栈。
一句话记忆:提示词定规矩,参数调精度。
强化理解:只会改提示词,就像只给员工发手册却不给工具;只调参数,就像给工具却不教用法。两者缺一不可。
以下示例展示如何通过编辑系统提示词+配置检索参数,将一个通用AI助手改造为“技术文档精准助手”。
对比新旧实现:
---- 旧方式:未编辑的通用 ---- def old_ai_search(query): return llm.invoke(f":{query}") 无任何约束 ---- 新方式:编辑后的精准 ---- from langchain_core.prompts import ChatPromptTemplate from langchain_community.retrievers import WikipediaRetriever 1. 编辑系统提示词(策略层) system_prompt = """ 你是一名技术文档研究员。资料时,必须遵循: - 优先来源:GitHub官方仓库、Stack Overflow高赞回答、arXiv论文 - 过滤规则:忽略2024年之前的资料 - 输出格式:每个回答后必须附上[来源链接] """ 2. 配置检索参数(执行层) retriever = WikipediaRetriever( top_k_results=5, 只取最相关的5个文档 doc_content_chars_max=500 每个文档最多取500字符 ) 3. 构建执行链 prompt = ChatPromptTemplate.from_messages([ ("system", system_prompt), ("human", "{question}") ]) def enhanced_ai_search(query): 先检索资料 docs = retriever.get_relevant_documents(query) context = "\n".join([d.page_content for d in docs]) 带提示词和检索结果调用LLM return llm.invoke(prompt.format(question=query, context=context)) 执行 result = enhanced_ai_search("2026年RAG技术最新进展") print(result)
关键步骤标注:
编辑系统提示词:定义了角色、来源偏好、过滤规则。
调优
top_k:控制召回数量,避免上下文过载。组合执行:先检索后生成,实现“先看资料再回答”。
底层依赖:这套配置机制高度依赖两个核心技术:
向量化嵌入(Embedding):将文本资料转换成高维空间中的向量,通过计算余弦相似度找到相关内容。
上下文窗口(Context Window):大模型内部的临时记忆区。
top_k和chunk_size的乘积必须小于上下文窗口,否则信息会被截断。
如何支撑上层:
向量检索支撑了“资料”的语义匹配能力,不再是简单的关键词匹配。
上下文窗口支撑了系统提示词+检索结果+用户问题的拼接能力。
定位:本文不深入源码,但请记住:编辑AI助手的过程,本质上是在利用嵌入模型筛选信息,然后利用大模型的上下文理解能力进行重组。这是未来深入LangChain或LlamaIndex等框架的基础。
八、高频面试题与参考答案1. 问:如何编辑AI助手,让它只最近一周的资料?
参考答案:
策略:在系统提示词中加入时间约束:“所有结果必须来自[2026-04-03至2026-04-10]”。
执行:同时,在检索参数中设置
date_filter字段(如果API支持),或在检索后增加一个基于时间戳的后过滤步骤。踩分点:区分策略层(提示词)和执行层(参数/代码过滤)。
2. 问:为什么编辑了系统提示词,AI助手还是搜出无关内容?
参考答案:
原因1:检索参数
top_k或similarity_threshold设置不当,召回了低质量分块。原因2:未对原始文档做合理的分块(Chunking),导致一个块中包含多主题。
解决:优化分块策略,调整
chunk_size和overlap,并提升相似度阈值。踩分点:指出问题可能不在提示词,而在检索管线。
3. 问:请简述编辑AI助手资料的核心流程。
参考答案:
第一步:编写系统提示词,定义角色、权威源、输出格式。
第二步:配置检索参数(
top_k,chunk_size,相似度阈值)。第三步:建立“检索-增强-生成”管线,将用户问题转为向量,获取资料后与提示词一同提交给大模型。
踩分点:逻辑清晰,点出“编辑”体现在提示词和参数两个维度。
核心知识点回顾:
怎么编辑AI助手资料 = 编辑系统提示词(策略层) + 调优检索参数(执行层)。
系统提示词管“做什么”,检索参数管“怎么做”。
底层依赖向量嵌入和上下文窗口。
重点与易错点:
不要只改提示词不改参数,二者需协同调整。
注意
top_k chunk_size不能超过模型上下文长度。
下篇预告:下一篇我们将深入分块(Chunking)策略,讲解如何通过语义分割与递归分块,让检索召回率提升50%。
 扫一扫微信交流
扫一扫微信交流