
北京时间2026年4月9日发布
一、开篇引入:为什么每个人都需要搞懂手机AI助手?
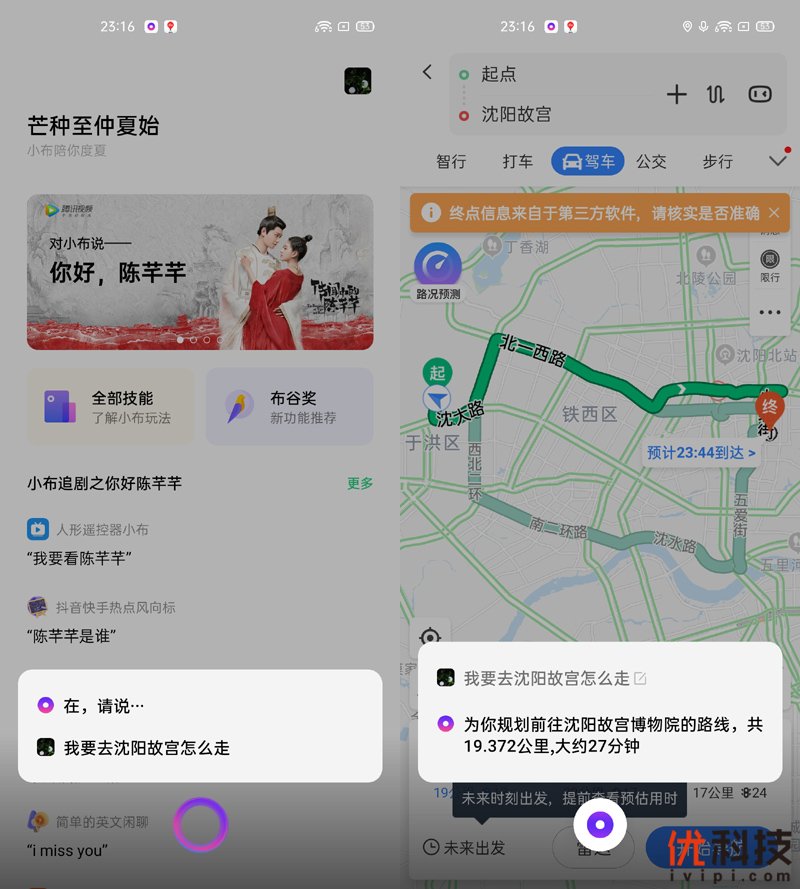
2026年被业界视为AI手机的真正爆发之年——春节前字节跳动豆包手机横空出世,节后三星S26系列以统一AI平台引发关注,realme也在realme UI 7.0中将小布助手全面升级,让AI功能深入系统骨髓-50-12。工信部部长李乐成在全国两会上明确提出,要推动AI手机更好满足人民群众的需求,AI智能体已成为全球智能手机行业的共同演进方向-50。
多数开发者在使用AI助手时面临着共同的困惑:只会喊“小布小布”,却搞不懂它为什么能听懂你的话;只会调用现成功能,却不明白背后从语音到意图再到执行的完整链路。面试中被问及“AI助手的核心技术栈”“意图分发如何实现”时,往往答不到核心要点。
本文将带大家从技术角度系统拆解realme AI助手的底层逻辑:从传统语音助手的痛点切入,深入概念辨析、架构剖析和原理探究,最后附上高频面试题解析,帮助你建立从“会用”到“懂原理”的完整知识链路。
二、痛点切入:传统语音助手为什么“不好用”?
在realme AI助手所依托的大模型技术出现之前,手机语音助手的体验存在诸多痛点。
传统的语音助手架构大致如下:
传统语音助手简化流程 def traditional_voice_assistant(): 1. 关键词唤醒 wake_word = listen_keyword() 持续监听“Hey Assistant” if not wake_word: return 2. 语音转文本 text = speech_to_text(capture_audio()) 3. 规则匹配 if "天气" in text: query_weather() elif "闹钟" in text: set_alarm(extract_time(text)) else: return "抱歉,我没听懂"
这种架构存在四个明显缺陷:
唤醒体验割裂:用户必须先喊出固定唤醒词才能下达指令,无法实现自然的连续对话。传统方案采用轻量级神经网络在设备端实时监听,功耗虽可控制在10mW以下,但无法处理“打断”“追问”等自然交互,且易受环境噪音干扰-56。
意图理解僵化:依赖规则匹配和关键词识别,用户必须以特定句式表达需求,“帮我设个明早八点的闹钟”和“明早八点叫我起床”可能被识别为两个不同的意图。
多轮对话能力弱:无法维持对话上下文,用户问完“今天天气怎么样?”后接着说“那明天呢?”,系统通常需要重新唤醒和完整表述。
缺乏主动服务能力:只能被动执行指令,不会根据用户场景主动推荐服务。
正是这些痛点,催生了以realme AI助手为代表的新一代大模型驱动型AI助手。
三、核心概念讲解:AI智能体(AI Agent)
标准定义
AI Agent(人工智能智能体) 是指能够感知环境、自主理解用户意图、规划任务步骤、调用工具/API完成目标并持续学习的智能实体。
关键词拆解
感知(Perception) :通过麦克风、摄像头、传感器等设备采集环境信息
决策(Decision) :利用大模型理解意图、规划任务路径
执行(Execution) :调用系统API或第三方应用完成具体操作
学习(Learning) :从用户反馈和行为数据中持续优化
生活化类比
想象你有一个私人助理:
传统语音助手 = 只会执行“去超市买瓶酱油”这种单一指令的实习生,换个说法就听不懂
AI Agent = 经验丰富的全能管家——你说“今晚家里来客人”,TA会主动考虑该准备什么菜、安排打扫、预约停车位,甚至根据你以往的口味偏好推荐菜单
在智能手机领域,AI Agent让AI从“屏幕里的对话者”转变为能够在真实场景中完成具体任务的智能实体,形成“感知—决策—执行”的完整闭环-47。
四、关联概念讲解:智能体手机(Agent Phone)
标准定义
智能体手机(Agent Phone) 是指从系统底层集成AI智能体能力、支持跨应用自动化任务执行的智能手机终端。
与AI Agent的关系
AI Agent是“能力”,智能体手机是“载体” ——就像“思考能力”和“大脑”的关系。AI Agent是技术理念和算法集合,而智能体手机是让这个理念落地的硬件+软件系统。
核心差异对比
| 维度 | AI Agent(能力层) | 智能体手机(产品层) |
|---|---|---|
| 定义 | 技术范式与算法 | 终端产品形态 |
| 关注点 | 如何理解、规划、执行 | 如何集成、交互、落地 |
| 典型应用 | 大模型推理、意图识别 | realme UI 7.0、豆包手机 |
| 可独立存在 | 是(如云端Agent) | 否(必须依赖硬件) |
运行机制简要说明
智能体手机的运行可以概括为“四步闭环”:感知 → 理解 → 规划 → 执行。
当你对realme AI助手说“帮我叫辆车去高铁站”时:
感知:麦克风采集语音信号,转为文本
理解:大模型解析意图为“出行叫车”,提取目的地“高铁站”
规划:拆解任务为“打开滴滴/高德 → 输入目的地 → 确认叫车”
执行:调用打车App完成操作
五、概念关系与区别总结
一句话总结:AI Agent是“大脑”,智能体手机是“身体”;AI Agent解决“怎么思考”,智能体手机解决“怎么落地” 。
AI Agent:侧重算法与能力——感知环境、理解意图、规划任务、调用工具
智能体手机:侧重产品与系统——系统级集成、跨应用执行、多模态交互、端云协同
二者的逻辑关系是 “设计思想 vs 实现载体” 。没有AI Agent,智能体手机只是硬件堆砌;没有智能体手机,AI Agent也只是云端无法触达用户的“空中楼阁”。
六、代码/流程示例:从语音到意图的完整链路
简化架构示意图
""" realme AI助手(基于小布助手)的简化处理流程 实际系统中涉及更复杂的工程实现,此处聚焦核心逻辑 """ 1. 语音采集与唤醒 class WakeUpEngine: """轻量级唤醒词检测模型""" def process(self, audio_stream): 采用轻量级神经网络(DNN/CNN)在设备端实时监听 功耗控制目标:<10mW,仅匹配预设唤醒词时激活主引擎 if self.detect_wake_word(audio_stream): return True return False 2. 语音识别(ASR) class SpeechRecognizer: """将语音信号转为文本""" def transcribe(self, audio): 基于端到端深度学习模型 流程:20-30ms分帧 → 梅尔频谱提取 → 声学模型识别 return text 3. 意图分发(关键模块) class IntentRouter: """判断query归属哪个垂域,是AI助手架构的核心瓶颈""" def route(self, query: str): 小爱同学的技术指标:意图分发需控制在200ms以内 采用“分而治之”思想:一个query进来后,先由大模型做意图分发 路由到下游垂域Agent(天气、闹钟、打车、知识问答等) 参考实现:基于大模型微调的few-shot分类器 domain = self.llm_classify(query) 天气 / 闹钟 / 打车 / 问答... return domain 4. 垂域意图理解 class DomainAgent: """各垂域的专用理解模型""" def understand(self, query: str, domain: str): if domain == "天气": 提取地点、时间等槽位 return {"intent": "query_weather", "slots": {"city": "上海", "date": "today"}} elif domain == "闹钟": return {"intent": "set_alarm", "slots": {"time": "08:00", "repeat": "weekdays"}} ... 其他垂域 5. 执行与响应生成 class ActionExecutor: """调用系统API或三方App""" def execute(self, intent, slots): if intent == "set_alarm": system.set_alarm(slots["time"], slots.get("repeat")) return {"success": True, "message": "已为您设置闹钟"} ... 完整流程串联 def realme_ai_assistant_pipeline(): 传统 vs 新一代对比 传统:唤醒 → ASR → 规则匹配 → 执行(单轮、僵化) 新一代:唤醒 → ASR → 意图分发(LLM) → 垂域理解(LLM) → 规划 → 执行(多轮、灵活) audio = microphone.capture() if WakeUpEngine().process(audio): text = SpeechRecognizer().transcribe(audio) domain = IntentRouter().route(text) intent = DomainAgent().understand(text, domain) result = ActionExecutor().execute(intent["intent"], intent["slots"]) return generate_response(result)
执行流程解释
唤醒检测:轻量级DNN/CNN模型在设备端持续监听音频流,仅当匹配唤醒词时才激活主系统,功耗控制在10mW以下-56
语音识别:将20-30ms的音频帧转换为梅尔频谱特征,通过声学模型输出文本-
意图分发:这是AI助手的核心瓶颈——一个query进来后,采用“分而治之”思想,先由大模型判断用户意图归属(天气/闹钟/打车/问答等),再路由到对应垂域Agent-44。小爱同学的技术要求是意图分发必须在200ms内完成-44
垂域理解:各垂域Agent使用专用模型进行深度意图识别和槽位填充
执行与响应:调用系统API或三方应用完成操作,生成自然语言回复
七、底层原理与技术支撑
核心技术栈一览
realme AI助手(以小布助手为能力核心)的技术栈可归纳为五层:
| 层级 | 核心技术 | 作用 |
|---|---|---|
| 感知层 | 麦克风阵列、NPU、多模态传感器 | 采集语音、屏幕状态、环境信息 |
| 唤醒层 | DNN/CNN关键词检测、上下文感知唤醒 | 低功耗唤醒,动态调整灵敏度-56 |
| 理解层 | 大语言模型、意图分发、槽位填充 | 语义理解、意图分类、信息抽取 |
| 知识层 | 知识图谱、持续预训练 | 问答推理、个性化记忆 |
| 执行层 | 系统API、三方App深度集成 | 跨应用自动化任务执行 |
底层技术支撑点
1. 大语言模型(LLM) ——这是新一代AI助手与传统助手之间最大的代际差异。大模型通过海量文本预训练获得了强大的语义理解能力,能够处理复杂指令和模糊表达。小布助手采用的自然语言处理模型融合了RNN、LSTM、注意力机制等技术,实现流畅的多轮对话-29。在回复生成阶段,大模型能够根据用户意图生成自然、个性化的回答-44。
2. 端侧推理与模型轻量化 ——手机端算力有限,大模型必须经过压缩才能在本地运行。技术路径包括:模型量化(FP16→INT8)、知识蒸馏、结构化剪枝等。小米小爱同学团队通过自研推理框架,实现了超过180 tokens/s的端侧推理速度-。
3. 意图分发架构 ——这是系统级的工程突破。采用“分而治之”思想:一个query进来后,由大模型做粗粒度意图分发(domain routing),再分发给下游各垂域Agent做细粒度理解。这种设计的优势在于:各垂域模型独立迭代,大幅降低整体开发难度和迭代成本-44。
4. 知识图谱 ——用于增强问答的准确性和深度。知识图谱通过对现有数据的挖掘和抽取,将信息融合为统一的全局知识库-。当用户询问复杂问题时,AI助手可以通过知识图谱进行多跳推理,给出更加全面的答案。
5. 端云协同 ——这是平衡性能、成本与隐私的关键设计。轻量级任务(如唤醒检测、简单指令)在端侧完成,保证毫秒级响应;复杂推理任务(如长文本问答、多轮对话)上云处理。端侧大模型被称为“本地化大脑”,让手机在本地独立完成大部分任务,仅在必要时协同云端,反应更快且更保护隐私-47。
八、高频面试题与参考答案
面试题1:请简述手机AI助手(如realme小布助手)的核心技术架构。
参考答案(分点作答,踩分点清晰):
手机AI助手的核心架构包含五个层次:
感知层:通过麦克风、摄像头、传感器采集环境与用户信息
唤醒层:基于轻量级神经网络(DNN/CNN)的关键词检测,功耗控制在10mW以下-56
理解层:大语言模型驱动的意图识别,采用“分而治之”的意图分发架构,先由大模型判断领域归属,再由垂域Agent做细粒度理解-44
知识层:知识图谱与个性化记忆,支撑问答推理与场景化服务
执行层:系统API调用与跨应用深度集成,实现自动化任务执行
加分点:补充端云协同策略(简单任务端侧处理、复杂任务上云)和意图分发耗时指标(<200ms)。
面试题2:大模型如何提升手机AI助手的用户体验?请举例说明。
参考答案:
大模型主要从三个方面提升体验:
理解能力的跃升:传统助手基于规则匹配,只能处理固定句式;大模型通过海量预训练具备语义理解能力,能处理“帮我设个明早八点的闹钟”和“明早八点叫我起床”等不同表达方式。
多轮对话能力:大模型的注意力机制和记忆网络可以维持对话上下文,用户问“今天天气怎么样?”后接着说“那明天呢?”,系统能自动维持对话状态,无需重复唤醒-29-56。
主动服务能力:结合用户场景和习惯,提供智能化推荐。例如realme UI 7.0的小布建议能在列车发车前15分钟推送检票提醒,在桌面显示生理周期卡片等-1。
加分点:引用具体数据——小爱同学引入大模型后,活跃用户次日留存提升10%,中长尾query满足率提升8%-44。
面试题3:手机AI助手中的“意图分发”模块是如何工作的?有什么技术挑战?
参考答案:
工作原理:意图分发采用“分而治之”的架构设计。用户query进入后,首先由意图分发大模型判断其所属领域(天气/闹钟/打车/问答等),然后将query路由到对应垂域的Agent进行深度理解。各垂域Agent仅关注自身垂直领域,便于独立迭代和优化-44。
技术挑战:
知识要求高:模型需要具备常识知识才能正确区分意图,例如“打开设置”vs“打开空调”,模型需要知道“设置”是系统项而“空调”是设备-44。
响应延迟要求苛刻:意图分发作为第一道关卡,响应速度直接影响用户体验。小爱同学的技术指标要求意图分发必须在200ms内完成-44。
小模型指令遵循能力有限:只有百亿级或千亿级的模型才能有效遵循指令输出预定义意图,小模型倾向于直接回答问题,需要采用微调而非简单的prompt engineering-44。
加分点:说明prompt engineering在延迟要求下的局限性(输入token过多),以及微调方案如何解决该问题。
面试题4:请比较传统语音助手与新一代大模型驱动AI助手的核心差异。
| 对比维度 | 传统语音助手 | 新一代大模型AI助手 |
|---|---|---|
| 理解方式 | 规则匹配 + 关键词识别 | 大模型语义理解 |
| 交互模式 | 单轮、唤醒-指令-响应 | 多轮、连续对话、自然打断 |
| 指令复杂度 | 简单、句式固定 | 复杂、口语化、模糊表达 |
| 服务模式 | 被动执行 | 主动感知 + 智能推荐 |
| 任务能力 | 单一步骤 | 多步骤规划 + 跨应用执行 |
| 核心瓶颈 | 意图覆盖不全 | 端侧算力限制 + 响应延迟 |
九、结尾总结
核心知识点回顾
AI Agent vs 智能体手机:前者是“大脑”和能力层,后者是“身体”和产品层,二者共同构成新一代AI助手的完整形态
意图分发架构:采用“分而治之”思想,大模型做领域路由,垂域Agent做细粒度理解,是当前业界的主流工程方案
端云协同:轻量级任务端侧处理(<10mW),复杂推理上云,兼顾功耗、响应速度和隐私安全
底层技术支柱:大语言模型(理解能力)+ 知识图谱(问答深度)+ 意图分发(系统效率)+ 端侧推理(本地化)
重点与易错点提示
易混淆点:AI Agent是技术范式,不要与具体产品名称(如“小布助手”)混淆
常见误区:认为AI助手就是“语音转文字+规则匹配”,实际上大模型时代的核心突破在于语义理解、多轮对话和主动服务
面试常考点:意图分发架构、端云协同策略、大模型与传统方案的本质差异
下一篇预告
本文聚焦于realme AI助手的整体架构与核心原理。下一篇我们将深入探讨端侧大模型的推理优化技术——如何在手机有限的算力资源下实现大模型的毫秒级响应,涵盖模型量化、投机推理、架构优化等实战技术,敬请期待。
📌 本文基于2026年4月9日的最新行业动态编写,适用于技术学习者、面试备考者和相关领域开发工程师。如需获取完整代码示例或交流讨论,欢迎留言互动。
 扫一扫微信交流
扫一扫微信交流